Заказные на статьи на Слешдоте
Вчера на Slashdot.com появилась статья про Путина и журавлей. И это на айтишном ресурсе, где даже статьи про политику вполне себе айтишные.
Сколько им заплатили?
Tags:
Вчера на Slashdot.com появилась статья про Путина и журавлей. И это на айтишном ресурсе, где даже статьи про политику вполне себе айтишные.
Сколько им заплатили?
Software that we now use constantly in our daily life wouldn't be possible if people creating these systems did not follow the practice of recording even the smallest change to the software in version control systems. Now, political activists all around the world convert legal texts to version control systems in an attempt to open up the lawmaking processes.
Now from FT.com.

На mova.org довольно давно работал XMPP сервер со свободной регистрацией. Недавно полез посмотреть, как он живёт, и обнаружил десять тысяч каких-то мутных пользователей , в ростере у них отсылки на syria talk, в оффлайн-сообщениях — фразочки разные по-арабски. Я их от греха подальше прибил, а теперь вот сижу и думаю — может, надо было разобраться сперва, а вдруг это была живая сеть, а не спамеры. А может, вся Сирия теперь корчится в огне тоталитаризма, потеряв связь… Лопухнулся, короче.
Just for record. The worst paper I ever wrote.
Instead of the usual
SELECT * FROM users WHERE uid=1;
type
SELECT * FROM users WHERE uid=1\G
and enjoy a much better formatting!
Internet trolls are using Tor nowadays to avoid bans by IP. However, banning Tor exit nodes is just slightly more complex. The Tor Project provides a regularly updated list of exit nodes that can access your IP here. As there may be many hundreds or even thousands of nodes, adding them to iptables can hurt your server's network performance. Enter ipset, a user-space hash table for iptables:
# create a new set for individual IP addresses ipset -N tor iphash # get a list of Tor exit nodes that can access $YOUR_IP, skip the comments and read line by line wget -q https://check.torproject.org/cgi-bin/TorBulkExitList.py?ip=$YOUR_IP -O -|sed '/^#/d' |while read IP do # add each IP address to the new set, silencing the warnings for IPs that have already been added ipset -q -A tor $IP done # filter our new set in iptables iptables -A INPUT -m set --match-set tor src -j DROP
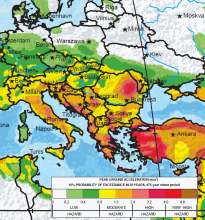
EU Observer runs a report on Belarus. See this gem: Earthquake zone on EU border to host Belarus nuclear plant.
Earthquake zone…