
European municipalities leak citizen data to US companies
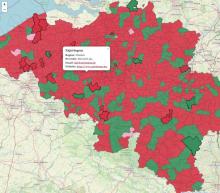
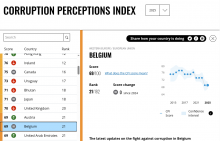
My favourite corruption story that I tell non-Belgians is the titres-services/dienstencheques racket.
Titres-services/dienstencheques is a kind of money that can be used only for household tasks. Think cleaning lady. At the introduction, they costed ~4.70€/hour to the public while designated organisations cashed in 21€/hour. The gap narrowed later, after creating a few nouveau riches, and after several scandals that were mostly about these people disrupting the office space market with their money.
The subsidy, initially at 16,30€ for every hour worked, came from public money, the stated reason was to draw household workers from the black market, the second reason was to achieve the goal of +100,000 jobs that the then Prime Minister set, the hidden objective was to enrich the few insiders, my memory does not serve me well, but IIRC the party affiliated with public service workers profited the most.
Google unilaterally restricts certificates to HTTPS usage only.
The most plausible explanation is that Google wants to push hardware vendors, more specifically companies like Worldpay that distribute payment terminals to use private PKI to avoid the next Symantec SHA-1 fiasco of 2016.
But the outcome is that we are now worse off as a society.
For all the royal f-ups of the Kingdom of Belgium, this one is the saddest. Someone had the idea to ban DeepSeek in the Belgian government. One of the few open weights frontier models that we can just take and run locally, without sharing our data with Chinese nor Americans, and they banned it.
How about SSH sending 100 IP packets on each keystroke?
In a similar vein, I recently ran into trouble upgrading Dovecot from 2.3 to 2.4.
There were lots of problems in this upgrade. For starters, Dovecot rewrote the configuration file syntax without incrementing the major version.
Then, they deprecated mbox support.
But the nastiest part was that when configured with pam authentication against system users, they run their own throttling service in parallel with the throttling done by pam in faillock.

Writing long documents in Word is painful to the point that people prefer to stick to old tools like FrameMaker.
It's also painful in a different way than LaTeX. While LaTeX is complex but deterministic, Word just eludes your efforts in a way that does not build a coherent mental model but rather a loose set of fuzzy rules learned via frustration.
I deeply believe that this was by design and it is part of Microsoft culture, created to separate programmers from users so that they suffer in their own ways. No wonder Bill Gates became a philanthropist in his later years. He knows better than anyone that future historians will figure out all the evil he expertly inflicted on the world.
Turns out, people lost the ability to have multiple profiles on the internet, and I think this due to costs. None wants to pay both to personal Gmail and to the business Google for Work, and if you have multiple identities, the bill goes up quite quickly, and the ease of use is nowhere to be seen.
I self-host my mail server, and I have a few domain names that all point to the same mail server via MX records in DNS.

One similarity between Putin and Ursula von der Leyen is they are both unelected leaders.
But another, more subtle one is that both lived for a long time in a bubble and have a much worse understanding of real-world matters than an average citizen.
It's common knowledge that Putin has been misled into believing that he can invade Ukraine in a matter of days. It became possible because not only the state hierarchy but also the state media adapted to fit the supreme leader, feeding him the news he wanted to hear.
Same thing but on a smaller scale happens to Ursula von der Leyen. Here's the story of the alleged GPS jamming of her plane as she flew to Plovdiv on 31 August 2025.
Original reports such as this one from the BBC were based on this morning press conference of von der Leyen press secretary Podesta.
This fake news spread by von der Leyen press secretary were quickly dismissed by FlightRadar24
Von der Leyen still has to repent in response to this parliamentary enquiry.
I self-hosted for well over 20 years, I did not throw the towel and I do not plan to. Self-hosting is a sign of pride. Neither my government nor my Prime Minister nor even my Ministry of Interior or Foreign Ministry can host their own email.
Last time I checked, only State Security self-hosted.
I was probably lucky, but I rarely had delivery problems. The last one was a couple years ago with Microsoft swallowing my emails and it was due to the combination of a fairly old exim and a TLS certificate verification quirk at *.protection.outlook.com. I found a fix in the form of a configuration option somewhere on SO.
In all fairness, there is very little maintenance involved, and whenever I have to do maintenance work, I take the opportunity to learn something new. Like this year, I decided to finally replace my aging Debian jessie setup by Arch Linux, and I rewrote all cron jobs as systemd timers.
I must admit that when I send a really important email, I check the mail server log if it went off without errors, but this does not bother me as checking logs manually once in a while is a good thing anyway.
Lastly, a piece of advice: treat self-hosting like a hobby and learn to enjoy it.
Oh and the very last thing: the person who designed Exim configuration for Debian deserves a special place in hell for all the hours wasted. If you set up Exim on Debian, just figure out how to use the upstream exim config and adapt it to your needs.

I had to use Rentio as a renter of an apartment, and the experience was so humiliating that the only way I can regain my human dignity is by writing about it.
Renters usually experience it via the website mytenantprofile.be or its French or Dutch counterparts where one can book a visit to an apartment or make an application to the landlord. The first sign of troubles ahead is that the website pushes the renter to provide the identity of the previous landlord while this should rather be discouraged, be it only for privacy reasons. But the real problems start when renters apply to multiple agencies.
The website does not make it clear, but it saves the first application and reuses it for the next. I have not found a way to adapt my profile to the second application, so I clicked the link to delete my profile, waited, then tried to create my profile anew just to be greeted with the message "Perfect, you have already used our service. We can reuse your data" and then when I try to reset my password via SMS, it announces "Too many requests generic error message" and an invitation to contact the support by email. I believe they break a few laws by not deleting my personal data and our Data Protection Authority should look closely into them, but I will follow this up in a different story.
Luckily, I had the phone number of the realtor, so I could call her, explain the problem and submit my application via email while waiting for Rentio support to fix my login issue.