
Software
Midwestern Mac, LLC: Solr for Drupal Developers, Part 2: Solr and Drupal, A History
Drupal has included basic site search functionality since its first public release. Search administration was added in Drupal 2.0.0 in 2001, and search quality, relevance, and customization was improved dramatically throughout the Drupal 4.x series, especially in Drupal 4.7.0. Drupal's built-in search provides decent database-backed search, but offers a minimal set of features, and slows down dramatically as the size of a Drupal site grows beyond thousands of nodes.
In the mid-2000s, when most custom search solutions were relatively niche products, and the Google Search Appliance dominated the field of large-scale custom search, Yonik Seeley started working on Solr for CNet Networks. Solr was designed to work with Lucene, and offered fast indexing, extremely fast search, and as time went on, other helpful features like distributed search and geospatial search. Once the project was open-sourced and released under the Apache Software Foundation's umbrella in 2006, the search engine became one of the most popular engines for customized and more performant site search.
As an aside, I am writing this series of blog posts from the perspective of a Drupal developer who has worked with large-scale, highly customized Solr search for Mercy (example), and with a variety of small-to-medium sites who are using Hosted Apache Solr, a service I've been running as part of Midwestern Mac since early 2011.
Timeline of Apache Solr and Drupal Solr IntegrationIf you can't view the timeline, please click through and read this article on Midwestern Mac's website directly.
A brief history of Apache Solr Search and Search API SolrOnly two years after Apache Solr was released, the first module that integrated Solr with Drupal, Apache Solr Search, was created. Originally, the module was written for Drupal 5.x, but it has been actively maintained for many years and was ported to Drupal 6 and 7, with some relatively major rewrites and modifications to keep the module up to date, easy to use, and integrated with all of Apache Solr's new features over time. As Solr gained popularity, many Drupal sites started switching from using core search or the Views module to using Apache Solr.
erdfisch: New module: Image widget default image
As part of a client project we recently had the requirement of displaying an image field's default image in the node add form, before the user had uploaded a picture. This seemed simple enough to implement but thinking about it I realized this was quite a generic feature request and that such a module might prove useful for others. Rather by accident I even noticed that Drupal.org itself employs the same feature on user profile pages.
Thus, I hereby present the Image widget default image module, which does just that: If you have provided a default image for an image field and the user has not yet uploaded an image for that field, it displays that default image as a preview. Not many bells or whistle, but it works. (I can claim that, because it comes with tests.
 ) If it does not work for you or if you have any questions please leave a comment or open an issue on Drupal.org.
) If it does not work for you or if you have any questions please leave a comment or open an issue on Drupal.org.

Code Karate: Multiple Views Part 2

In part 2 of the multiple views series you will learn how to add the jQuery needed to switch between multiple classes. By having the ability to use multiple classes, we will (in part 3) be able to use CSS to change the look and feel of the same view.
Here is the jQuery code used to switch between grid and list view:
Tags: DrupalViewsDrupal 7Theme DevelopmentDrupal PlanetJavascriptJQueryDrupalCon Amsterdam: Training spotlight: Professional Agile Project Management For Drupal Projects
Over 30 people attended this wildly successful training at DrupalCon Austin. Now is your chance to attend this training at DrupalCon Amsterdam!
In this course, we cut past the evangelism that exists around Agile, and instead focus on real-world practical training that you can put into action.
The course is delivered using the Agile Scrum techniques it teaches. At the start, delegates see the backlog of requirements that the product owner (a trainer) has developed for the course, and the prioritization of those requirements. The course then progresses in one-hour periods of work called sprints, working through training modules from the top of the backlog.
Part way through the morning, delegates are ready to take over as the product owners. They will take responsibility for specifying the requirements for the course, based on the needs and interests of the delegates in the room, re-prioritise them, and even add completely new requirements. Our trainers will respond to these changes by creating new training modules on the fly based on real project experience, to provide the highest possible value to the delegates.
Through this approach we demonstrate and explain the processes of Agile many times, and we also demonstrate their value, and delegates leave with a real insight into how they could apply agile, and handle some of the challenges they may have faced.
The trainers are highly experienced Agile coaches, who mentor teams at Wunderkraut (known as WunderRoot in the UK), as well as consulting with large clients about ensuring successful delivery of their projects.
Meet the Trainers from WunderkrautSteve Parks (steveparks), UK Managing Director
Vesa Palmu (wesku), CEO
Roel De Meester (demeester_roel), CTO Benelux
Florian Huber (fuber), Project Manager, Scrum Master
This training will be held on Monday, 29 September from 09:00-17:00 at the Amsterdam RAI during DrupalCon Amsterdam. The cost of attending this training is €400 and includes training materials, meals and coffee breaks. A DrupalCon ticket is not required to register to attend this event.
Our training courses are designed to be small enough to provide attendees plenty of one-on-one time with the instructor, but large enough that they are a good use of the instructor's time. Each training course must meet its minimum sign-up number by 5 September in order for the course to take place. You can help to ensure your training course takes place by registering before this date and asking friends and colleagues to attend.
Four Kitchens: DrupalCamp Twin Cities: Frontend Wrap-up
This year’s Twin Cities DrupalCamp had no shortage of new faces, quality sessions, trainings, and after parties. Most of my time was spent in frontend sessions and talking with folks. Being that I live in Minneapolis, this camp is especially rewarding from a hometown Drupal represent kind of perspective. Below are some of my favorite sessions and camp highlights.
Community DrupalMediacurrent: UX - Above the Fold & Scrolling

More and more often I am asked, when putting together a design Drupal for a website, what is the importance of designing above the fold and whether or not that today’s users will scroll to read content.
Drupal Association News: Drupal Association Values
 In my experience as an organization leader one of the most important tools in my toolbox has always been my personal values. It's been my experience that even when data points in one direction, and best practices say you should approach the problem in this way, it's always been my values that help me make the best decisions as an individual. And the truth is, there are very rarely any decisions that are 100% clear cut. In almost every decision, some amount of judegment is required.
In my experience as an organization leader one of the most important tools in my toolbox has always been my personal values. It's been my experience that even when data points in one direction, and best practices say you should approach the problem in this way, it's always been my values that help me make the best decisions as an individual. And the truth is, there are very rarely any decisions that are 100% clear cut. In almost every decision, some amount of judegment is required.
That's why I believe so strongly in defining values for the organizations I work for. When everyone is working from a shared sense of values, we're making decisions - even big giant judgement calls - from the same perspective. To that end, we spent some time this year working with the board and staff to develop a values statement for the Drupal Association.
We started in a board retreat, brainstorming the implicit (though not documented) values of the Association and the larger Drupal Community. The board ranked their favorites, and then we created a committee of board and staff to draft some language. Those initial values statements were vetted by both the entire Association staff and the full board, and then additional edits were made. Here's the result of that process:
The Drupal Association shares the values of our community, our staff, and open source projects:
- TEAMWORK: We add value to the Drupal community by helping each other solve problems to create quality human and digital experiences.
- COMMUNICATION: We value communication. We seek community participation. We are open and transparent.
- ACTION: We act decisively and proactively, embracing what we learn from both our successes and our mistakes.
- RESPECT: We respect and value inclusivity in our global community and strive to recognize, understand, and respond to its needs.
- FUN: We create environments that embrace humor resulting in fun, positive, supportive and safe interactions.
To be clear, these are the values we're defining for our staff. We're not trying to impose these values on the larger community. However, we do hope they reflect the values you feel are important in the larger Drupal community as well. We also want to recognize that writing down the words is one thing, and living up to them is something else. We intend to live these values in all our work.
Now it's your turn. The values are set by the board and staff, but we want to make sure we know what you think.
Flickr photo: Howard Lake
Nuvole: Git workflow for managing Drupal 8 configuration
This is a preview of Nuvole's training at DrupalCon Amsterdam: An Effective Development Workflow in Drupal 8.
One of the new key features of Drupal 8 is the possibility to deal with configuration in code. Since configuration is now in text files, we want to put it under version control in Git to enjoy the many advantages this brings: comparing configuration states, keeping a history of configuration changes and even moving configuration between sites.
SetupWe will assume that you have a development version of Drupal 8, git and drush available on your system.
You can set up your Drupal git repository in several ways. One of them is outlined in Building a Drupal site with Git on drupal.org. The document is written for Drupal 7, but can easily be adapted for Drupal 8.
Another, probably simpler method is to simply download a Drupal 8 (alpha) release and initialise a new repository with it.
In either case you should copy example.gitignore to .gitignore and adapt it to your needs to prevent settings.php and the files directory from being versioned.
The next step is to make sure that a configuration directory is versionable. By default Drupal 8 will place the staging directory under sites/default/files and it is considered a good practice to not version that location, but an alternative location can easily be specified in settings.php:
<?php$config_directories['staging'] = 'config/staging';
?>
It is also possible and even advisable to specify a directory outside of the web root of course. In that case you would put the parent directory of your web root where drupal is under version control and use ../config/staging. We will later see that it is also possible to add more directories and keys to the $config_directories variable.
Because the configuration management of Drupal 8 only works between different instances of the same site, the different instances of the site need to be cloned. Cloning a Drupal 8 site is done the same way as cloning a Drupal 7 site. Just dump the database of the site to clone and import it in the other environment.
DevelopmentAfter cloning your site you can go ahead and start configuring your site.
Once the part of the configuration you were working on is done the whole configuration of the site needs to be exported.
The current contents of your export directory (config/staging) will be deleted. (y/n): y
Configuration successfully exported to config/staging.
Next, you need to merge the work of other developers. In some cases it may be enough to simply use git pull, otherwise the configuration has to be merged after it has been committed:
Add all configuration to git and commit it.
Use git pull (or git fetch and git merge) and resolve any conflicts if necessary.
Git can merge changes in text files quite well, but git does not know about Drupal and its yaml format for configuration. It is, therefore, important to verify that the merged configuration makes sense and is valid. In most cases it will probably not be an issue and just work, but it is always better to be vigilant and be on the safe side. So, after merging, you should always run:
local$ drush config-import stagingIf the import went smooth you can push the configuration to the remote repository. Otherwise the configuration needs to be fixed first.
DeploymentThe simplest case is when the configuration on the production site has not been changed. There is an interesting Configuration Read-only mode module that can enforce this.
If the configuration did not change deploying the new configuration is simply:
remote$ git pullremote$ drush config-import staging
If the configuration changes on the production site, it is best to frequently export the live configuration into a dedicated directory.
Add a new config directory in settings.php:
$config_directories['to_dev'] = 'config/to_dev';
?> remote$ drush config-export to_dev -y
Add, commit and push it to the production branch so that the developers can deal with it and integrate the changes into the configuration which will be deployed next. Exporting the configuration into a dedicated directory rather than the staging directory avoids the danger that merge conflicts happen on the production site. The deployment to the production site should be kept hassle free, so it should always be safe to pull from git and import the configuration without the risk of a conflict.
Important notesIt is important to first export the configuration changes and then pull changes from collaborators because the exporting action wipes the directory and re-populates it with the active configuration. Since everything is in git, you can recover from such a mistake without much difficulty but why make your life complicated.
Import the configuration before pushing it to the remote repository. Broken configuration breaks the site, be a nice co-worker.
Git doesn't solve everything! Imagine Alice and Bob start with the same site, it has one content type and among others an "attachment" field. Alice deletes the attachment field, exports the configuration and pushes it to git. In the meantime, Bob creates a new content type and adds the attachment field to it. Bob exports his configuration, merges Alice's configuration changes without a problem (the changes are separate files) and imports the merged configuration. The attentive reader sees where this leads. The commit of Alice deletes the field storage for the attachment field, but Bob added a field instance which depends on the field storage.
The exported configuration now contains a field instance that can't be imported.
At the time of writing, drush will signal a successful import but doesn't actually import it while the UI is more helpful and complains that the attachment field instance was not imported due to the missing field storage.
Acquia: Drupal 8 & Empowerment through Drupal
Part 1 of a 2-part conversation with Angie Byron in front of the cameras at NYC Camp 2014. In this part of our conversation we go over some of the inspiring and thought-provoking ideas we encountered there, and then jump to some of the benefits to users of the technical improvements built into Drupal 8.
Kristian Polso: How to create Drupal Commerce products programmatically
Modules Unraveled: 115 Drupal Core Gittip Team with Jennifer Hodgdon, Bojhan Somers Alex Pott and Cathy Theys - Modules Unraveled Podcast
 Published: Wed, 08/20/14Download this episodeGitTip
Published: Wed, 08/20/14Download this episodeGitTip
-
What is GitTip? How does it work?
-
What is a GitTip team?
-
How did the Drupal Core team come about? What prompted it’s genesis?
-
Who is the organizer of the Drupal Core team, and who is benefiting from it?
19 members, Alex and Cathy are administering the group, a couple are on vacation.
16 others are taking money. -
On the GitTip page it says your goal is $5,000 US/week. What would that cover?
Cathy: This week is the first week that we will not be able to fund the modest goal of giving people $64/week. The past few weeks we have been paying out $700. We have now eaten all our balance and have only $350 coming in this week.
The $5k goal is what a guess at funding 6 people about ¼ time. -
What have you all been working on lately as a result of this funding?
Cathy: tips are for work already done, so… I'm not sure. Maybe it motivates future work, or planning to be able to do future work? Jen? Bojhan?
What has this funding enabled you to do?
PreviousNext: Drupal 8 Now: PHPUnit tests in Drupal 7
Drupal 8 comes with built-in support for PHP Unit for unit-testing, the industry standard for unit-tests.
But that doesn't mean you can't use PHP Unit for your testing and CI in Drupal 7, if you structure your code well.
Read on to find out what you need to do to use PHP Unit in Drupal 7.
Phase2: Profiling Drupal Performance with PHPStorm and Xdebug
Profiling is about measuring the performance of PHP code, at least when we are talking about Drupal and Xdebug. You might need to profile your site or app if you work at a firm where performance is highly scrutinized, or if you are having problems getting a migration to complete. Whatever the reason, if you have been tasked with analyzing the performance of your Drupal codebase, profiling is one great way of doing so. Note that Xdebug’s profiler does not track memory usage. If you want to know more about memory performance tracking you should check out Xdebug’s execution trace features.
Alright then lets get started!Whoa there cowboy! First you need to know that the act of profiling your code is itself taking resources to accomplish. The more work your code does, the more information that the profiler stores; file sizes for these logs can get very big very quickly. You have been warned. To get going with profiling Drupal in PHPStorm and Xdebug you need:
To setup your environment, edit your php.ini file and add the following lines:
xdebug.profiler_output_dir=/tmp/profiler/ xdebug.profiler_enable=on xdebug.profiler_trigger=on xdebug.profiler_append=onDepending on what you are testing and how, you may want to adjust the settings for your site. For instance, if you are using Drush to run a migration, you can’t start the profiler on-demand, and that affects the profiler_trigger setting. For my dev site I used the php.ini config you see above and simply added a URL parameter “XDEBUG_PROFILE=on” to my site’s url; this starts Xdebug profiling from the browser.
To give you an idea of what is possible, lets profile the work required to view a simple Drupal node. To profile the node view I visited http://profiler.loc/node/48581?XDEBUG_PROFILE=on in my browser. I didn’t see any flashing lights or hear bells and whistles, but I should have a binary file that PHPStorm can inspect, located in the path I setup in my php.ini profiler_output_dir directive.

Finally lets look at all of our hard work! In PHPStorm navigate to Tools->Analyze Xdebug Profile Snapshot. Browse to your profiler output directory and you should see at least one cachgrind.out.%p file (%p refers to the process id the script used). Open the file with the largest process id appended to the end of the filename.

We are then greeted with a new tab showing the results of the profiler.

The output shows us the functions called, how many times they were called, and the amount of execution time each function took. Additionally, you can see the hierarchy of all function calls and follow potential bottlenecks down to their roots.
There you have it! Go wild and profile all the things! Just kidding, don’t do that.
Phase2: Profiling Drupal Performance with PHPStorm and Xdebug
Profiling is about measuring the performance of PHP code, at least when we are talking about Drupal and Xdebug. You might need to profile your site or app if you work at a firm where performance is highly scrutinized, or if you are having problems getting a migration to complete. Whatever the reason, if you have been tasked with analyzing the performance of your Drupal codebase, profiling is one great way of doing so. Note that Xdebug’s profiler does not track memory usage. If you want to know more about memory performance tracking you should check out Xdebug’s execution trace features.
Alright then lets get started!Whoa there cowboy! First you need to know that the act of profiling your code is itself taking resources to accomplish. The more work your code does, the more information that the profiler stores; file sizes for these logs can get very big very quickly. You have been warned. To get going with profiling Drupal in PHPStorm and Xdebug you need:
To setup your environment, edit your php.ini file and add the following lines:
xdebug.profiler_output_dir=/tmp/profiler/ xdebug.profiler_enable=on xdebug.profiler_trigger=on xdebug.profiler_append=onDepending on what you are testing and how, you may want to adjust the settings for your site. For instance, if you are using Drush to run a migration, you can’t start the profiler on-demand, and that affects the profiler_trigger setting. For my dev site I used the php.ini config you see above and simply added a URL parameter “XDEBUG_PROFILE=on” to my site’s url; this starts Xdebug profiling from the browser.
To give you an idea of what is possible, lets profile the work required to view a simple Drupal node. To profile the node view I visited http://profiler.loc/node/48581?XDEBUG_PROFILE=on in my browser. I didn’t see any flashing lights or hear bells and whistles, but I should have a binary file that PHPStorm can inspect, located in the path I setup in my php.ini profiler_output_dir directive.
Finally lets look at all of our hard work! In PHPStorm navigate to Tools->Analyze Xdebug Profile Snapshot. Browse to your profiler output directory and you should see at least one cachgrind.out.%p file (%p refers to the process id the script used). Open the file with the largest process id appended to the end of the filename.
We are then greeted with a new tab showing the results of the profiler.
The output shows us the functions called, how many times they were called, and the amount of execution time each function took. Additionally, you can see the hierarchy of all function calls and follow potential bottlenecks down to their roots.
There you have it! Go wild and profile all the things! Just kidding, don’t do that.
DrupalCon Amsterdam: Schedules, BOFS, & Training in Amsterdam
The schedule for DrupalCon Amsterdam is live, which means that you can start planning out every detail of your Amsterdam experience. You can start the hard work of choosing the sessions, BOFs, and social events you want to attend, and build your own schedule right on the DrupalCon Amsterdam site.
BOF scheduling is liveSpeaking of BOFs, you don’t have to wait until DrupalCon Amsterdam to claim yours: you can start using the online booking feature today to schedule your BOFs. Be sure you do it soon, though— BOF rooms go fast!
Register for training before 5 SeptemberLastly, we need more people to register to attend training at DrupalCon Amsterdam. Show us you're interested in these topics! Book before 5 September to make sure the course you want to attend runs. We know it's difficult to make a decision this early out, but classes which do not meet the minimum to run will be cancelled!
The training options are all fantastic and a great opportunity to learn more about Drupal, so register today.
See you in Amsterdam!
Drupalize.Me: Upgrading Drush to work with Drupal 8
When I first started learning Drupal, I remember the process of enabling and disabling modules on the Modules page and it took for-ev-er. My laptop was in serious danger of getting hurled across the room, due to my frustration. Then I discovered drush, and downloading and enabling modules was now performed with ease instead of pain and suffering. Of course there's a lot more you can do with drush than just download and enable modules, this is just one example.
I've been using Drush 6.x on my local machine for quite some time now. Poking around Drupal 8's UI and seeing what's new, I haven't missed drush too much...until it was time to test drive a new contrib module for Drupal 8. When I typed into my Terminal window drush dl page_manager, I got quite the error message:
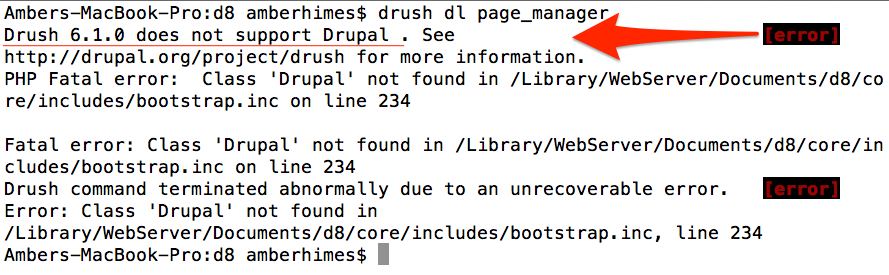
Drush 6.x only works with Drupal 6 or 7. If I wanted to use Drush on my Drupal 8 site, I would need to upgrade to Drush 7.x.
Drupalize.Me: Upgrading Drush to work with Drupal 8
When I first started learning Drupal, I remember the process of enabling and disabling modules on the Modules page and it took for-ev-er. My laptop was in serious danger of getting hurled across the room, due to my frustration. Then I discovered drush, and downloading and enabling modules was now performed with ease instead of pain and suffering. Of course there's a lot more you can do with drush than just download and enable modules, this is just one example.
I've been using Drush 6.x on my local machine for quite some time now. Poking around Drupal 8's UI and seeing what's new, I haven't missed drush too much...until it was time to test drive a new contrib module for Drupal 8. When I typed into my Terminal window drush dl page_manager, I got quite the error message:

Drush 6.x only works with Drupal 6 or 7. If I wanted to use Drush on my Drupal 8 site, I would need to upgrade to Drush 7.x.
ComputerMinds.co.uk: Language lessons: What are you translating?
It seems an obvious question to ask, but what are you translating?
The tools exist to translate just about anything in Drupal 7*, but in many different ways, so you need to know exactly what you're translating. Language is 'a first-class citizen', in the sense that any piece of text is inherently written by someone on some language, which Drupal 7 is built to recognise. Sometimes you want to translate each & every individual piece of text (e.g. at the sentence or paragraph level). Other times you want to translate a whole page or section that is made up of multiple pieces of text.
Joachim's blog: Getting Module Builder ready for Drupal 8
I've just made a commit to Module Builder that adds unit tests. This is a big deal, because having these frees me up to start making the big changes that are needed for supporting Drupal 8's new structures: routes, plugins, forms, and so on.
The biggest challenge is going to be the interface. Currently, you give Module Builder just a module name and a list of hook names, and it does the necessary. On the command line it's nice and simple:
drush mb mymodule install schema node_insert form_alter views_data_alter
The first parameter is the module name, and everything that follows is a hook name. Now we add to the mix requests such as a form called MyModuleCakeToppingForm, or an entity type plugin, or a route bake_my_cake and its page controller. How to elegantly specify all that over the command line, without making it horribly unwieldy and impossible to remember how to use?
It's also going to be an interesting exercise in reading my own documentation and seeing how much sense it makes after something like 7 months away from the code.
From what I recall, Module Builder uses a hierarchy of component generators to build your module. Taking our example above, the first thing that happens is that the Module generator class kicks in. 'So, you want a module, do you?' it asks, 'You'll need some of these.' And it begins to assemble a list of further generators, for the components it needs: an info file, and the hooks generator. The hooks generator does the actual job of examining your list of requested hooks, and decides based on that that you need three code files: a .module, a .install, and a .views.inc. So by now we have a tree of generators like this:
- Module -- Info file -- Hooks --- Code file: .module --- Code file: .install --- Code file: .views.incThis is not a class hierarchy; this is a tree of objects where each generator has a list of the generators beneath it, and is responsible for collecting data from them. Once we have the tree, we iteratively have each generator assemble the data it wants to contribute, starting with the Module generator at the top.
The original plan when I wrote this system was to make the smallest granularity be a file. The leaves of the generator tree would assemble the text for their file's contents, and the Module generator would collect the files up and return them to the caller for output (either in the UI, or to write them directly).
However, while the original intention of this system was that it could be generalised to base components other than modules (so profiles and themes, which are both supported to some extend but lack the UI, see above!), it's also proven to be extendable downwards to smaller components, and to be worthwhile to do so.
Enter the Form generator. Once we have a generic Function generator (and its child class the HookImplementation), we can create a Form generator. Given a form machine name, 'foo_form', it simply knows to add three copies of the Function generator: 'foo_form', 'foo_form_validate', 'foo_form_submit', along with the correct parameters and some boiler plate code.
And we can specialize this further: the AdminSettingsForm simply extends the Form generator, and adds a menu item component, which itself ensures hook_menu() is requested.
At this point it starts to get a bit complicated, as we have components that request other components that are in totally different parts of the component tree. That's the point at which I think I was when I realized I needed tests so that I can refactor and clean up the messy bits of this, and enhance and extend it, without breaking what's already there.
So that's the current state of Module Builder: not yet ready for Drupal 8, but has lots of potential. At this point, I'd really welcome input on the Drush interface, as that's the big quandary. And any input on new Drupal 8 component generators would be great too; there are a few open issues in the queue. And finally, Module Builder is a complex beast; should anyone looking at the code find it baffling and impenetrable, do please file a documentation issue to highlight the problem and request clarification.
Daniel Pocock: Is WebRTC private?
With the exciting developments at rtc.debian.org, many people are starting to look more closely at browser-based real-time communications.
Some have dared to ask: does it solve the privacy problems of existing solutions?
Privacy is a relative termPerfect privacy and its technical manifestations are hard to define. I had a go at it in a blog on the Gold Standard for free communications technology on 5 June 2013. By pure co-incidence, a few hours later, the first Snowden leaks appeared and this particular human right was suddenly thrust into the spotlight.
WebRTC and ICE privacy riskWebRTC does not give you perfect privacy.
At least one astute observer at my session at Paris mini-DebConf 2014 questioned the privacy of Interactive Connectivity Establishment (ICE, RFC 5245).
In its most basic form, ICE scans all the local IP addresses on your machine and NAT gateway and sends them to the person calling you so that their phone can find the optimal path to contact you. This clearly has privacy implications as a caller can work out which ISP you are connected to and some rough details of your network topology at any given moment in time.
What WebRTC does bring to the tableSome of this can be mitigated though: an ICE implementation can be tuned so that it only advertises the IP address of a dedicated relay host. If you can afford a little latency, your privacy is safe again. This privacy protecting initiative could be made by a browser vendor such as Mozilla or it can be done in JavaScript by a softphone such as JSCommunicator.
Many individuals are now using a proprietary softphone to talk to family and friends around the world. The softphone in question has properties like a virus, siphoning away your private information. This proprietary softphone is also an insidious threat to open source and free operating systems on the desktop. WebRTC is a positive step back from the brink. It gives people a choice.
WebRTC is a particularly relevant choice for business. Can you imagine going to a business and asking them to make all their email communication through hotmail? When a business starts using a particular proprietary softphone, how is it any different? WebRTC offers a solution that is actually easier for the user and can be secured back to the business network using TLS.
WebRTC is based on open standards, particularly HTML5. Leading implementations, such as the SIP over WebSocket support in reSIProcate, JSCommunicator and the DruCall module for Drupal are fully open source. Not only is it great to be free, it is possible to extend and customize any of these components.
What is missingThere are some things that are not quite there yet and require a serious effort from the browser vendors. At the top of the list for privacy:
- ZRTP support - browsers currently support DTLS-SRTP, which is based on X.509. ZRTP is more like PGP, a democratic and distributed peer-to-peer privacy solution without needing to trust some central certificate authority.
- TLS with PGP - the TLS protocol used to secure the WebSocket signalling channel is also based on X.509 with the risk of a central certificate authority. There is increasing chatter about the need for TLS to use PGP instead of X.509 and WebRTC would be a big winner if this were to eventuate and be combined with ZRTP.
You may think "I'll believe it when I see it". Each of these features, including WebRTC itself, is a piece of the puzzle and even solving one piece at a time brings people further out of danger from the proprietary mess the world lives with today.